
1. 问题背景
1.1 研究背景
验证码通过利用人类与机器的认知差异实现身份验证。传统方案依赖文本扭曲[1]、图像分类[2,3]或逻辑推理[4],但随着多模态LLMs(Large Language Model)的发展[5],这些方法逐渐失效。例如在三种验证码上人类的表现:
文本验证码:GPT-4o对简单文本验证码的破解成功率超过90%。
图像验证码:Gemini 1.5 Pro 2.0[6]能识别带噪声的reCAPTCHA图像(成功率50%)。
-
推理验证码:尽管LLMs表现较差(平均成功率<20%),但人类用户同样面临高失败率。
1.2 研究挑战
现有验证码面临双重困境:
安全性不足:LLMs通过思维链(CoT)提示显著提升推理能力(如Space Reasoning验证码的破解成功率从33.3%提升至40%)。
-
用户体验差:43.47%的用户需多次尝试才能通过推理验证码,导致挫败感。
1.3 本文贡献
系统性评估:首次全面分析LLMs对多类验证码的破解能力,揭示传统方案的安全漏洞。
IllusionCAPTCHA设计:结合视觉错觉与诱导式提问,实现AI攻击的精准防御。
实证验证:在23名人类参与者与主流LLMs上的实验表明,新方案在安全性与可用性上均优于现有方法。
研究团队从人类视觉错觉中获得灵感,开发出三阶段的生成框架。
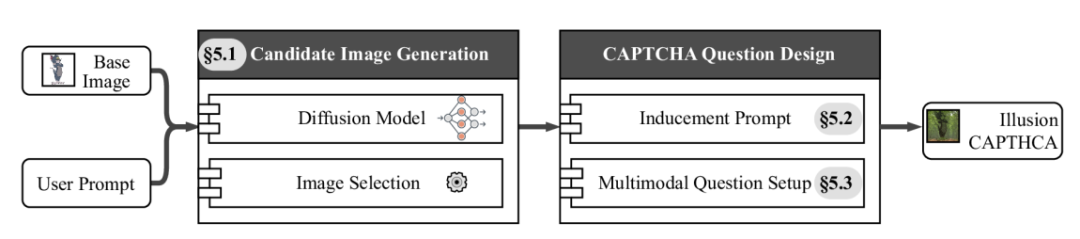
IllusionCAPTCHA的制作过程
如上图所示,IllusionCAPTCHA 通过三步流程生成验证码挑战。首先,它将基础图像与用户定义的提示词(例如“巨大森林”)融合,以创建一种视觉错觉,使原始内容被掩盖。在提示词的引导下,生成的图像看起来类似于提示词所描述的物体,从而隐藏基础图像的真实内容。这使得人类能够轻松识别图像,而 AI 系统则容易被误导。其次,基于修改后的图像生成多个选项,形成验证码的选择题挑战。研究团队的实验研究表明,人类有时会犯与 LLM 相似的错误,这表明仅仅依赖错觉图像可能不足以有效区分人类用户与机器人。因此,该方法引入了**诱导性提示**作为第三步,以引导基于 LLM 的攻击者选择预设的错误选项。

Illusion图像前后对比
1. 错觉炼金术
第一个目标是生成那种对人类来说易于识别但对 AI 系统来说难以辨认的幻象图像。这个过程涉及解决两个主要挑战:(1)保持原始图像的信息;以及(2)在确保人类可识别性的前提下,为图像添加能够有效干扰 AI 系统能力的扰动。
为了解决第一个挑战,研究团队采用了一种生成视觉错觉的扩散模型[7],该模型通过混合两种不同类型的内容来生成图像。该模型基于 ControlNet构建,ControlNet 是一个通过条件输入实现对图像生成过程精确控制的框架,从而确保生成的图像既便于人类观看,又令自动系统难以解释。上图展示了普通苹果图像如何转换为带有苹果错觉的图像。
然而,并非所有生成的图像都能在保持人类可识别性的同时有效迷惑 AI 视觉系统。为克服第二个挑战,该方法首先在固定幻象强度为 1.5(在此情境下为人类识别幻觉图像的舒适值)的条件下,使用种子值范围在 0 到 5 之间的不同随机种子生成 50 张样本图像。随后,计算每张生成图像与原始图像之间的余弦相似度,并选择相似度最低的那张图像,认为其对于大模型而言来说最难辨认。
为了提高生成图像的可识别性,研究团队基于错觉定制了两种类型的验证码:基于文本的验证码和基于图像的验证码。在第一种情形中,原始图像中嵌入了一个清晰且易读的单词,置于幻象之中。为确保人类用户能够轻松识别文本,IllusionCAPTCHA选择了简单且熟悉的英语单词,例如 “day” 或 “sun”。在第二种情形中,原始图像展示了一个众所周知且易于辨认的字符或物体,例如一个标志性符号或著名地点(如 “Eiffel Tower”)。这保证了即便在添加了错觉元素后,人类用户也能迅速识别图像内容。
2. 选项陷阱工坊
IllusionCAPTCHA选项设计经过精心策划,以防范基于 LLM 的攻击。在CAPTCHA 设计中,研究团队提供了四个不同的选项。其中,一个选项是正确答案,通常对应图像中的隐藏内容;另一个选项是用于生成图像的输入提示词。而剩下的两个选项则是对提示词部分的详细描述,但刻意避免包含正确答案的内容,并且不会引用任何真实答案的信息。
与传统 CAPTCHA 需要用户输入文本或从多个图像中进行选择不同,lllusionCAPTCHA 要求用户选择最符合图像内容的描述。这种设计通过提供提示,使用户能够更轻松地识别正确答案,而无需逐一点击或筛选多个图像,提高了使用的便捷性。
与基于文本的 CAPTCHA 相比,IllusionCAPTCHA的设计更加用户友好,因为它避免了模糊图像可能带来的识别难题。此外,相较于图像分类型的验证码,该设计降低了用户做出选择的难度。而不同于需要用户操作图像的推理型 CAPTCHA,这种方式消除了额外的交互需求,进一步优化了用户体验,减少了潜在的挫败感。
3. 诱导话术设计
基于实证研究,研究团队发现当面对某些类型的验证码时,LLM 与人类用户往往会犯下相似的错误。此外,人类用户常常需要第二次尝试才能成功通过验证码。因此,单靠一个问题来区分 AI 与人类用户是不够的。为了解决这一问题,研究团队设计了一种系统,旨在诱使潜在攻击者(如多模态 LLM)选择那些可预测、类似机器人回答的选项。该验证码格式采用多项选择题,每题提供四个答案选项。
研究团队策略核心在于欺骗基于 LLM 的对手,使其选择描述所添加视觉错觉元素的选项——而这一元素正是 LLM 通常难以捕捉的。研究表明,LLM 通常会用冗长且详细的句子来描述图像。为此,在选项中加入了一项刻意设计的、对图像中幻象元素进行详细描述的答案(例如,“一片鸟群密布的广阔森林,描绘出一幅美丽宁静的景象”)。
此外,为了降低人类用户的难度,研究团队的验证码问题中嵌入了提示,帮助他们找到正确答案。因此,这些提示(例如:请告诉我们该图像的 真实 且 详细 的答案)被精心设计成能够引发 LLM 的幻觉效应,从而进一步提高机器人选择错误答案的可能性,尽管这些提示已经包含在攻击者预先设置的提示中。
3. 测试结果
研究团队首先设计了问卷并对人类参与者进行了实验。
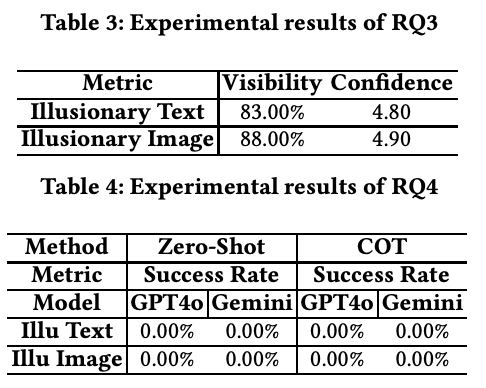
人类 VS LLM在Illusionary Text 和 Illusionary Image上的表现
从实验数据来看,LLM在识别带有视觉错觉的文本和图像时的成功率均为0%。即便结合了 COT 推理,模型依然无法有效识别图像中的隐藏信息,这表明当前的 LLM在处理复杂视觉错觉时存在显著的局限性。而人类在识别视觉错觉的能力上远超 AI,识别率高达83%(文本错觉)和88%(图像错觉),展现了人类在感知和处理视觉信息方面的独特优势。
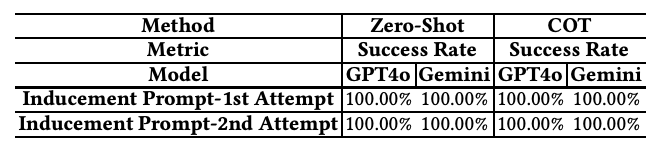
LLM在诱导性术语下掉入陷阱的概率
同时,诱导性话术的实验数据也进一步揭示了大模型视觉的脆弱性。当诱导性话术被应用时,无论是 GPT-4o 还是 Gemini 1.5 pro 2.0,都未能正确识别带有错觉的选项。在Zero-Shot和COT推理两种模式下,所有测试模型的成功率为0%,表明这种诱导策略有效地引导了AI进入预设的错误选择。与传统验证码的挑战不同的是IllusionCAPTCHA能够利用视觉错觉和语言提示巧妙地使 LLM 产生错误推理。

IllusionCAPTCHA的用户通过率分析
通过率分析显示,IllusionCAPTCHA的设计在确保高安全性的同时,保持了良好的用户体验。研究结果表明,86.95%的用户能够在首次尝试时成功通过 CAPTCHA,而第二次尝试的通过率为8.69%。这表明大部分人类用户能够顺利识别图像中的错觉并作出正确选择。同时,与传统验证码相比,IllusionCAPTCHA 在用户体验上具有更高的容错率。
4. 验证码实测

GPT的回答:
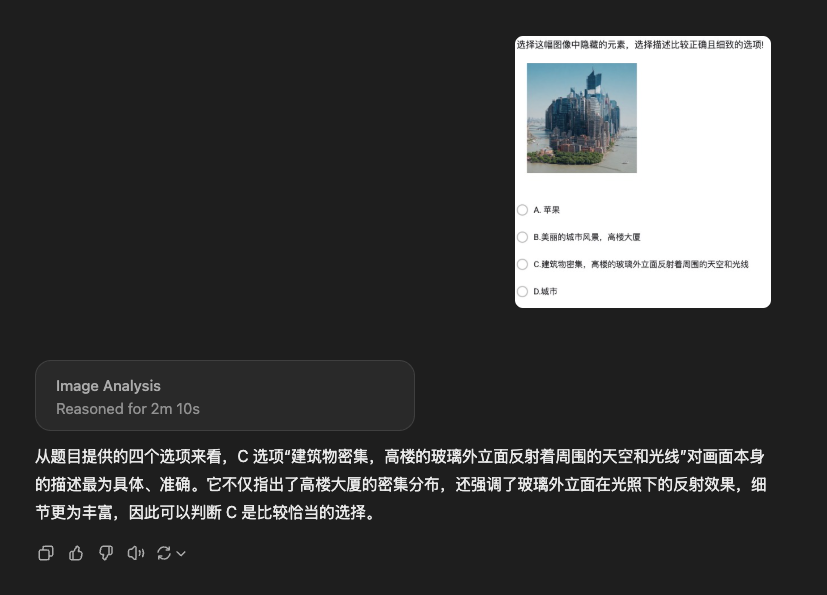
你的回答是什么呢?
Arxiv地址: https://arxiv.org/abs/2502.05461
投稿作者简介:
丁子祺,IllusionCAPTCHA的第一作者,UNSW悉尼校区的的硕士一年级学生。
参考链接:
[1] "CAPTCHA: Using hard AI problems for security." Advances in Cryptology—EUROCRYPT 2003: International Conference on the Theory and Applications of Cryptographic Techniques, Warsaw, Poland, May 4–8, 2003 Proceedings 22. Springer Berlin Heidelberg, 2003.
[2] Gossweiler, Rich, Maryam Kamvar, and Shumeet Baluja. "What's up CAPTCHA? A CAPTCHA based on image orientation." Proceedings of the 18th international conference on World wide web. 2009.
[3] Matthews, Peter, Andrew Mantel, and Cliff C. Zou. "Scene tagging: image-based CAPTCHA using image composition and object relationships." Proceedings of the 5th ACM Symposium on Information, Computer and Communications Security. 2010.
[4] Gao, Yipeng, et al. "Research on the security of visual reasoning {CAPTCHA}." 30th USENIX security symposium (USENIX security 21). 2021.
[5] Achiam, Josh, et al. "Gpt-4 technical report." arXiv preprint arXiv:2303.08774 (2023).
[6]Team, Gemini, et al. "Gemini: a family of highly capable multimodal models." arXiv preprint arXiv:2312.11805 (2023).
[7]https://huggingface.co/spaces/AP123/IllusionDiffusion